The key to a worldwide service: Availability
How RTK From the Sky achieves 99.999% correction service availability

RTK From the Sky correction technology is the latest innovation from Hexagon’s Autonomy & Positioning division. Combining the best qualities of Real-Time Kinematic (RTK) and Precise Point Positioning (PPP), RTK From the Sky technology has demonstrated that instant global centimetre-level accuracy is now possible. This development is a remarkable world-first achievement, bringing new possibilities for high precision applications.
Now the question is: how do you bring this successful research initiative to worldwide users as a full-fledged operational service? To meet the demands of diverse applications and challenging GNSS environments, engineering efforts must focus in on three core aspects of a high-quality correction service: convergence time, accuracy and availability. Together, this trifecta enables the consistent performance of rapidly-converging, centimetre-level accuracy in RTK From the Sky technology. Convergence time and accuracy are well-known specifications to describe positioning performance, but service availability is the key that enables this positioning experience – it is the foundation upon which a correction service achieves rapid convergence and precision accuracy. Availability describes the percentage of time a service is available for use; without a stable correction stream, high accuracy and fast convergence are inaccessible.
RTK From the Sky technology is designed for 99.999% global service availability. This high level of availability requires a thorough analysis of each component of the system, a comprehensive system design, robust validation and constant monitoring. This blog post discusses what 99.999% availability means for GNSS correction services and how we achieve this for RTK From the Sky.
What is 99.999% correction service availability?
Availability is measured and communicated by a percentage of uptime – for highly available systems, this is typically described by a number of ‘Nines’. For a system or service that runs 24 hours a day and 365 days a year, the number of Nines has a large impact on the overall experience of the service. However, availability describes more than when the service is functioning; it also describes the quality of its performance in achieving both high precision accuracy and fast convergence each and every time. A service that is broadcasting corrections, but not providing centimetre accuracy and fast convergence, is not actually available.
Hexagon’s global correction services provide five Nines (99.999%) of availability. This means the services may accumulate no more than 5.3 minutes of outages over the course of the year. Compare that to a two Nine (99%) system, which could experience 14.6 minutes of downtime a day, adding up to 3.7 days total over the year. At first glance, 99% may seem like incredible coverage, but when you break it down by time, every Nine matters – especially if your application can’t afford any downtime.
| Nines | Availability | Allowable Outage Time per Year |
|---|---|---|
| 2 Nines | 99% | 3.7 days |
| 3 Nines | 99.9% | 8.8 hours |
| 4 Nines | 99.99% | 53 minutes |
| 5 Nines | 99.999% | 5.3 minutes |
To achieve 99.999% availability, we thoroughly analyse each component of the positioning ecosystem to understand their respective failure rates and how they behave together in the larger system. These relationships are represented with AND/OR gates.
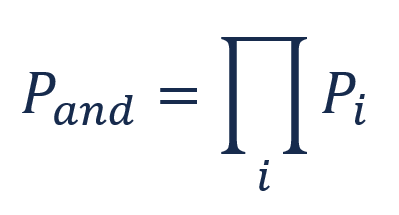
Figure 1: The AND Gate formula. The overall failure rate is the product of the failure rate of each component. Parallel circuits are an example of AND gates. AND gates decrease the overall failure rate.
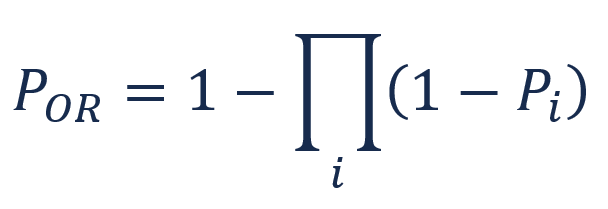
Figure 2: The OR Gate formula. The overall failure rate is the union of the failure rate of each component. Series circuits are an example of OR gates. OR gates increase the overall failure rate.
Let’s visualise these concepts with the following examples. Each bar represents the status of a system component over time, highlighting periods of failure (or unavailability) in orange. In this example, each component has a failure rate of 25%.
In an AND configuration, the primary system only fails when Component 1 AND Component 2 fail. This design decreases the probability of a total system outage to 6.25%:
PAND = (0.25)(0.25) = 0.0625 = 6.25%
The overall system experiences an outage only when all AND components are unavailable:
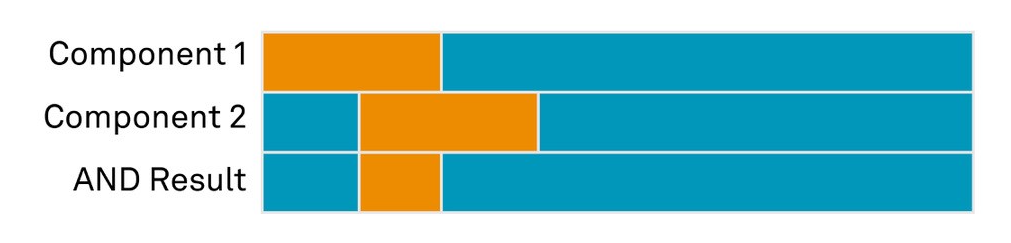
If the AND components fail at different times, the primary system does not experience an outage:
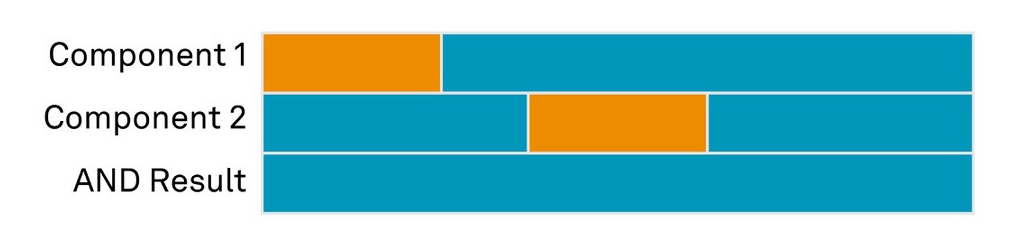
For components organised in an OR configuration, the system fails when Component 1 OR Component 2 fails. This design increases the likelihood of an outage, to 43.75%:
POR = 1 - [(1 - 0.25)(1 - 0.25)] = 0.4375 = 43.75%
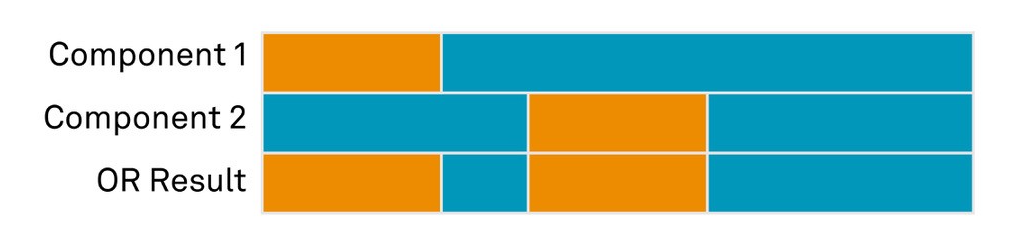
These examples show how the availability of a total system depends on each individual component’s availability and the system’s AND/OR gate design. This type of analysis enables us to identify and minimise potential failures. Our services are designed around these statistical concepts to ensure the lowest failure rate and the highest availability possible.
Building a redundant correction service positioning system
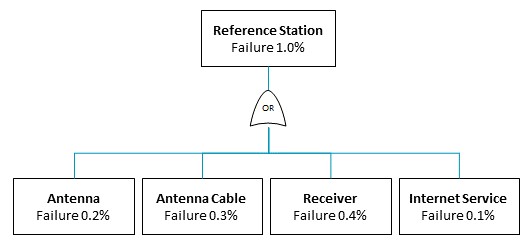
Figure 3: This fault tree visualizes how, if any one of the reference station's components fail, the station will be unable to transmit data.
Now let’s see how these AND/OR gates are used in Hexagon’s correction services. The following figures show some of the main components of a correction system. Possible failures the system could experience would be power outages, signal interference or jamming, physical or cybersecurity threats, Internet service provider (ISP) failures and more. The impact of these failures can be understood and broken down by looking at fault tree diagrams with AND/OR gates (note that the failure rates used in these examples are hypothetical and selected for the purposes of our explanation).
Let’s start with a fault tree diagram for a GNSS reference station, which is shown here in Figure 3. You can see that the antenna, antenna cable, receiver and ISP service are combined through an OR gate, which means that we will have an outage at this site if any of these components fail. By using the OR equation above, the probability of the station failure is 1.0%.
We can enhance the availability of the site by building in a backup reference station, as shown in Figure 4. Although the backup station has the same components and same failure rate as the primary station, the AND connection between the two stations drastically improves the overall site failure. Using the AND equation, the site failure rate is now 0.01%, a significant improvement from the single station probability of 1.0%.
In this configuration, if the primary station experiences an outage, the backup will continue transmitting data to the control centre. This design also provides the critical opportunity to detect and fix the issue without impacting service for end-users. This is an example of built-in redundancy and is found in systems where there is an AND gate.
When you look at a simplified fault tree for the service (Figure 5) you can see that these redundant AND gates are found throughout the design: we maintain a global reference station network optimally designed for redundancy, two control centres on different continents each with two correction computation systems, multiple L-Band satellites, Internet protocol (IP) options for correction delivery and more.
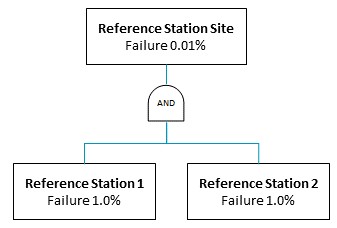
Figure 4: This fault tree illustrates how the reference station can continue operation regardless if the primary or the backup systems experience a system outage thanks to its AND gate.
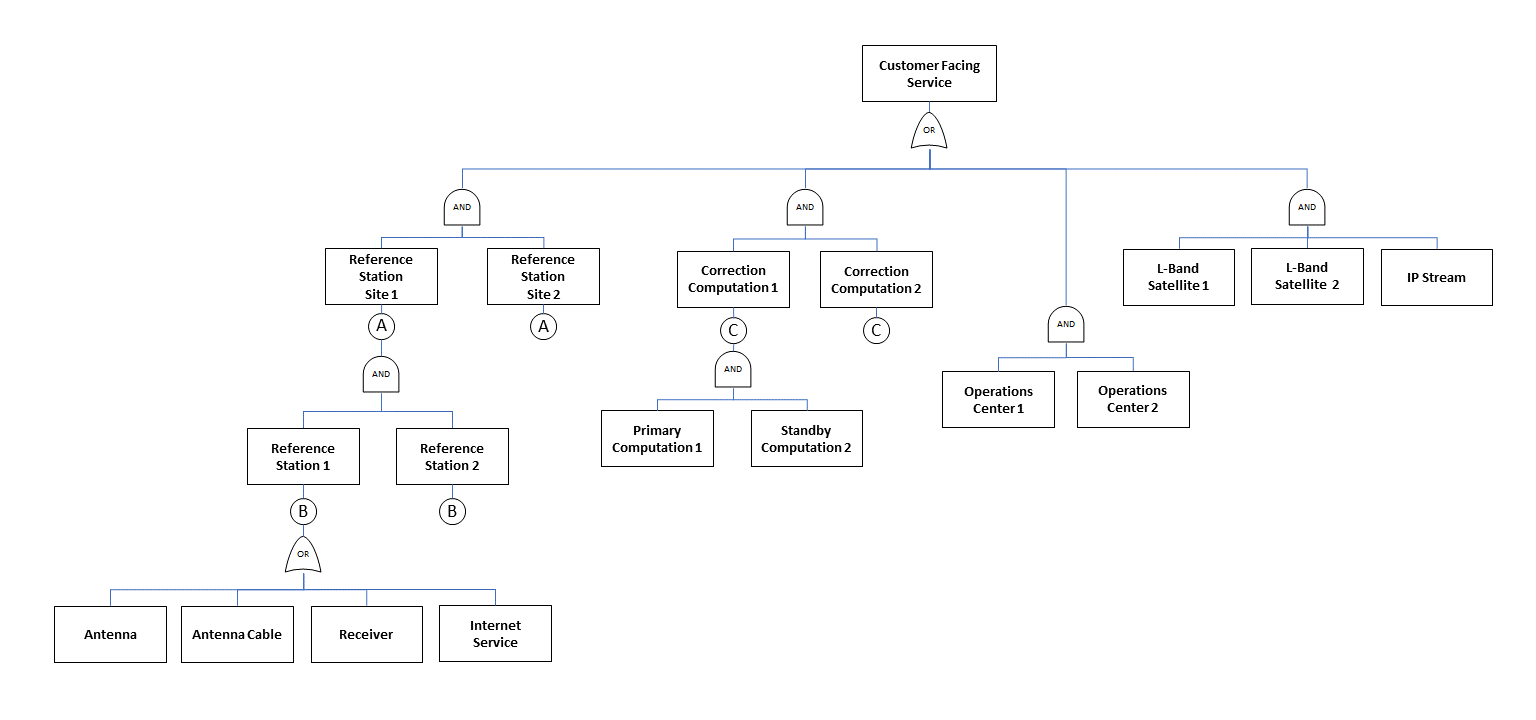
Figure 5: A positioning ecosystem built with AND gates optimises system redundancy and maintains continuous operations.
Figure 5 represents only a small snapshot of a larger correction service system. Hexagon has invested significant time and infrastructure resources to build a fully redundant system and developed processes to efficiently identify causes of errors and outages. It enables us to actively react to and mitigate outages that would threaten the five Nines availability seen in RTK From the Sky.
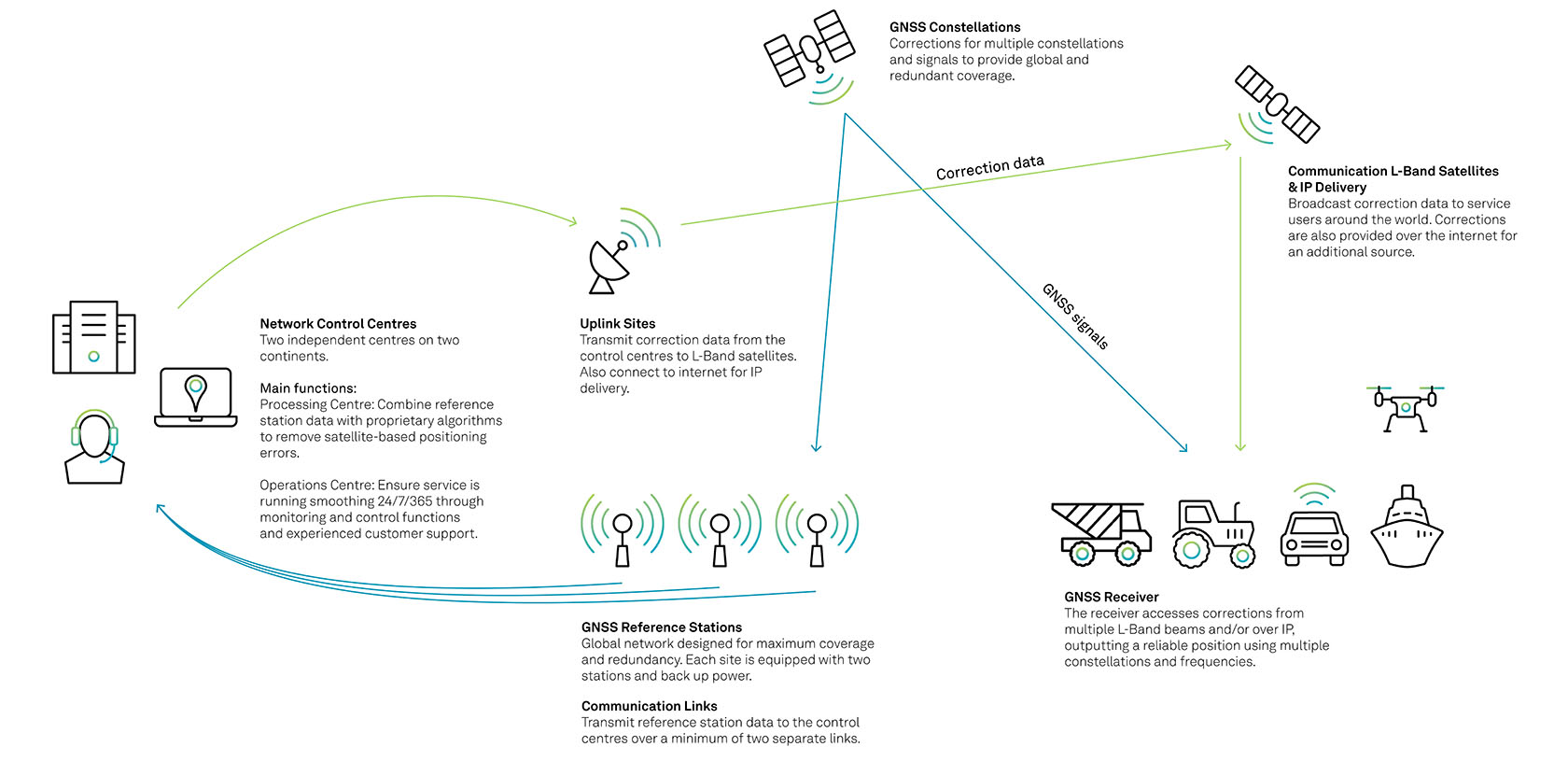
Figure 6: A generalised example of our correction services system, including the multiple operational control and computation centres where our teams monitor system performance and availability.
Our redundancy was put to the test when, on December 10th 2019, there was a power surge followed by an outage at the primary Network Control Centre (NCC) in Aberdeen, UK. End-users did not experience any issues thanks to the layering of uninterrupted power supply systems and an auto-start generator for the building. Further, the switch to the backup NCC in Singapore was possible through the consistent monitoring from our engineering teams. Service performance and our 99.999% availability were upheld through these monitoring efforts.
Monitoring in action: Maintaining availability during Galileo’s December 2020 service issues

Figure 7: Operators at our correction network control centres are constantly monitoring potential disruptions and outages. In December 2020, they noticed Galileo's service disruption before the European GNSS Agency notified users.
Availability starts with design but is maintained through high-quality monitoring protocols. RTK From the Sky technology benefits from robust monitoring tools and highly experienced teams who quickly identify and respond to any failures. These teams work around the clock on two continents and are a fundamental piece of our high availability. There are countless stories of how the operators analysed and solved problems to switch to backup corrections, backup stations, disabled unhealthy satellites and generally protected the service with essential saves to keep the service operational, with no impact to service quality and end-users.
Let’s look at an example of a real-life failure. On December 14, 2020, the Galileo satellite constellation experienced service interruptions. Our operations monitoring systems reported that Galileo was performing sub-optimally across our primary and standby systems. Once the problem was confirmed by our on-call engineers, we decided to temporarily disable Galileo across Hexagon’s services. This decision mitigated any potential outage of our services.
With a robust system and adept monitoring protocols, we identified a change in service availability, investigated its source, mitigated potential outages, and continued providing high-quality positioning to our end-users. In this case, our monitoring systems and operators detected and responded to Galileo’s service issues before the European GNSS Agency sent their official notification of a service issue.
In addition to our system redundancy with dual reference stations, data transmission hardware and multiple computation and operational control centres, the efforts of the monitoring operators mitigate events that would otherwise cause service quality changes or disruptions. Monitoring is key to the overall system redundancy and availability achieved in RTK From the Sky.
Consistent performance and 99.999% availability through operational redundancy
Convergence time and accuracy are used to describe a correction service’s performance, but service availability remains the key to enabling high quality performance. This trifecta supports the performance demonstrated with RTK From the Sky technology and is made possible through operational redundancy and monitoring stations.
We uphold our 99.999% availability and high level of performance uptime through robust system designs and skilled teams. RTK From the Sky is our next-generation technology to leverage this long-standing expertise and innovation in service delivery.